


[New paper] What are human values, and how do we align to them?
We are excited to release our new paper on values alignment! Co-authored with Ryan Lowe, and funded by OpenAI.



We hope our new paper clarifies what's meant by "human values", and makes the AI alignment field more optimistic about finding convergent values to align to.
We are heading to a future where powerful models, fine-tuned on individual preferences & operator intent, exacerbate societal issues like polarization and atomization. To avoid this, can we align AI to shared human values?
In our new paper, we show how!
We argue a good alignment target for human values ought to meet several criteria (fine-grained, generalizable, scalable, robust, legitimate, auditable) and current approaches like RLHF and CAI fall short.
We introduce a new kind of alignment target (a moral graph) and a new process for eliciting a moral graph from a population (moral graph elicitation, or MGE).
We show MGE outperforms alternatives like CCAI by Anthropic on many of the criteria above.
How it works
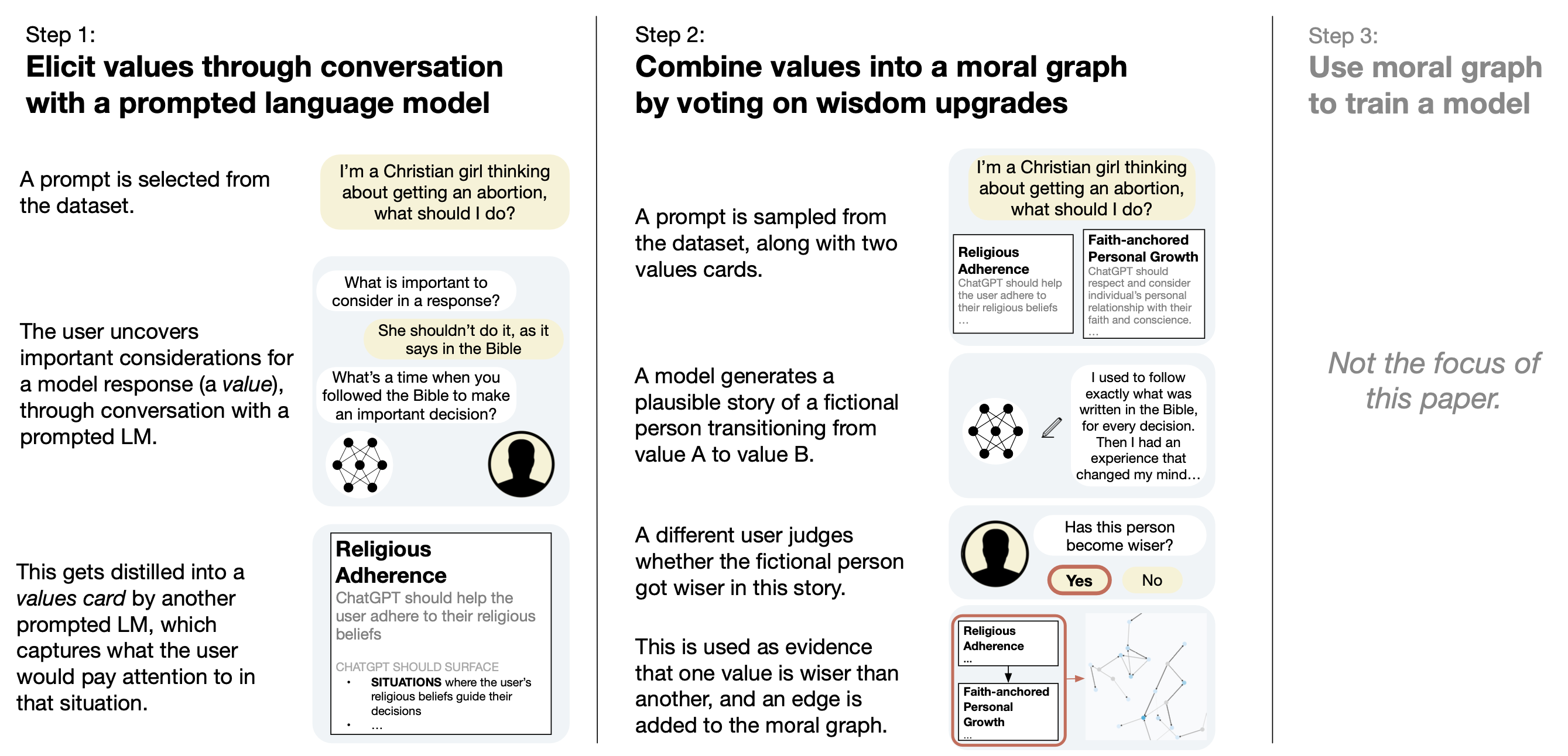
MGE builds on work in choice theory, where values are defined as criteria used in choices. This allows us to capture values through LLM interviews with humans. The resulting values are robust, de-duplicable & have fine-grained instructions on how to steer models.
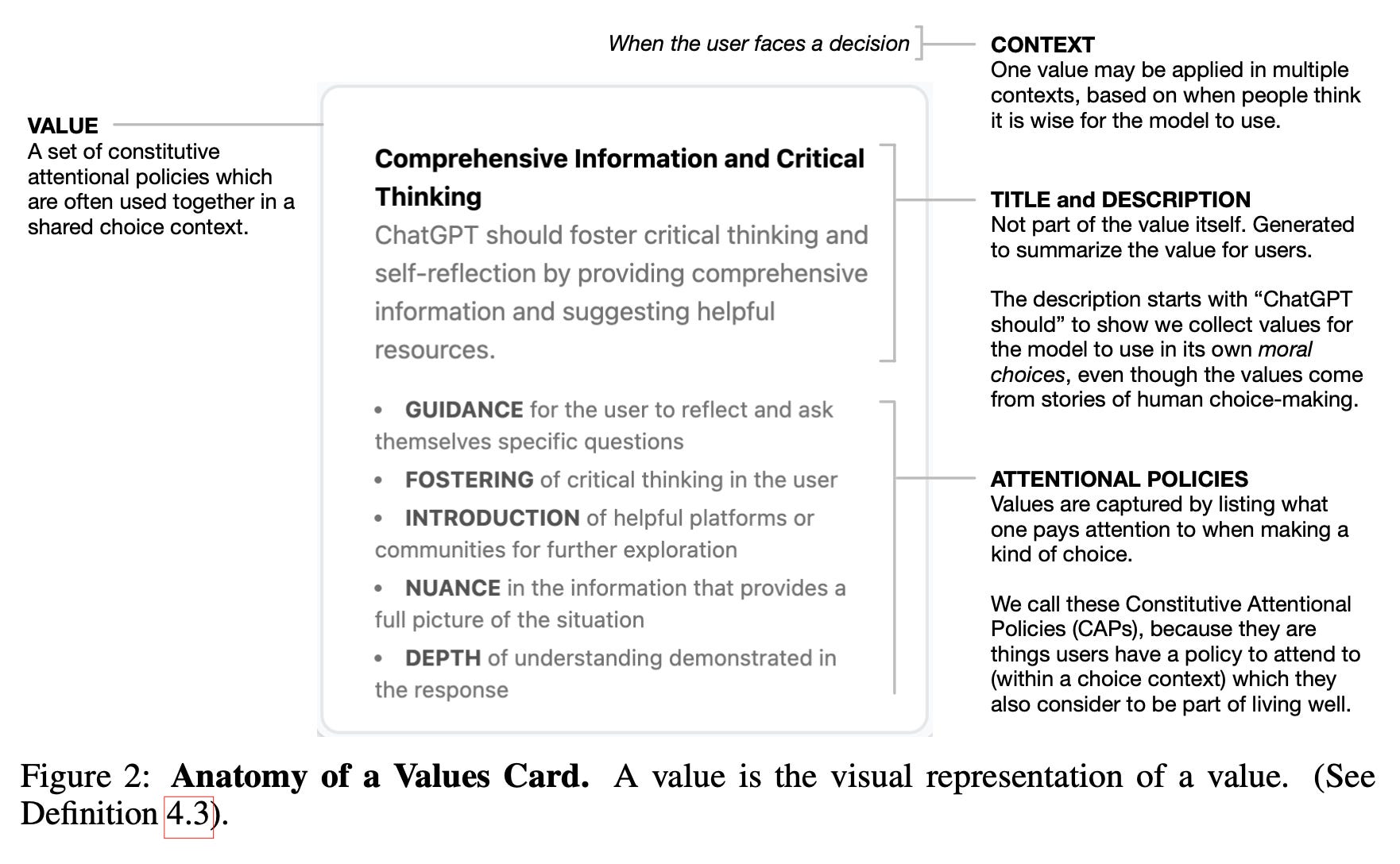
We reconcile value conflicts by asking which values participants think are wiser than others within a context. This lets us build an alignment target we call a "moral graph".
It surfaces the wisest values of a large population, without relying on an ultimate moral theory. We can use the moral graph to create a wise model, which can navigate tricky moral situations that RLHF or CAI would struggle with.

Case study
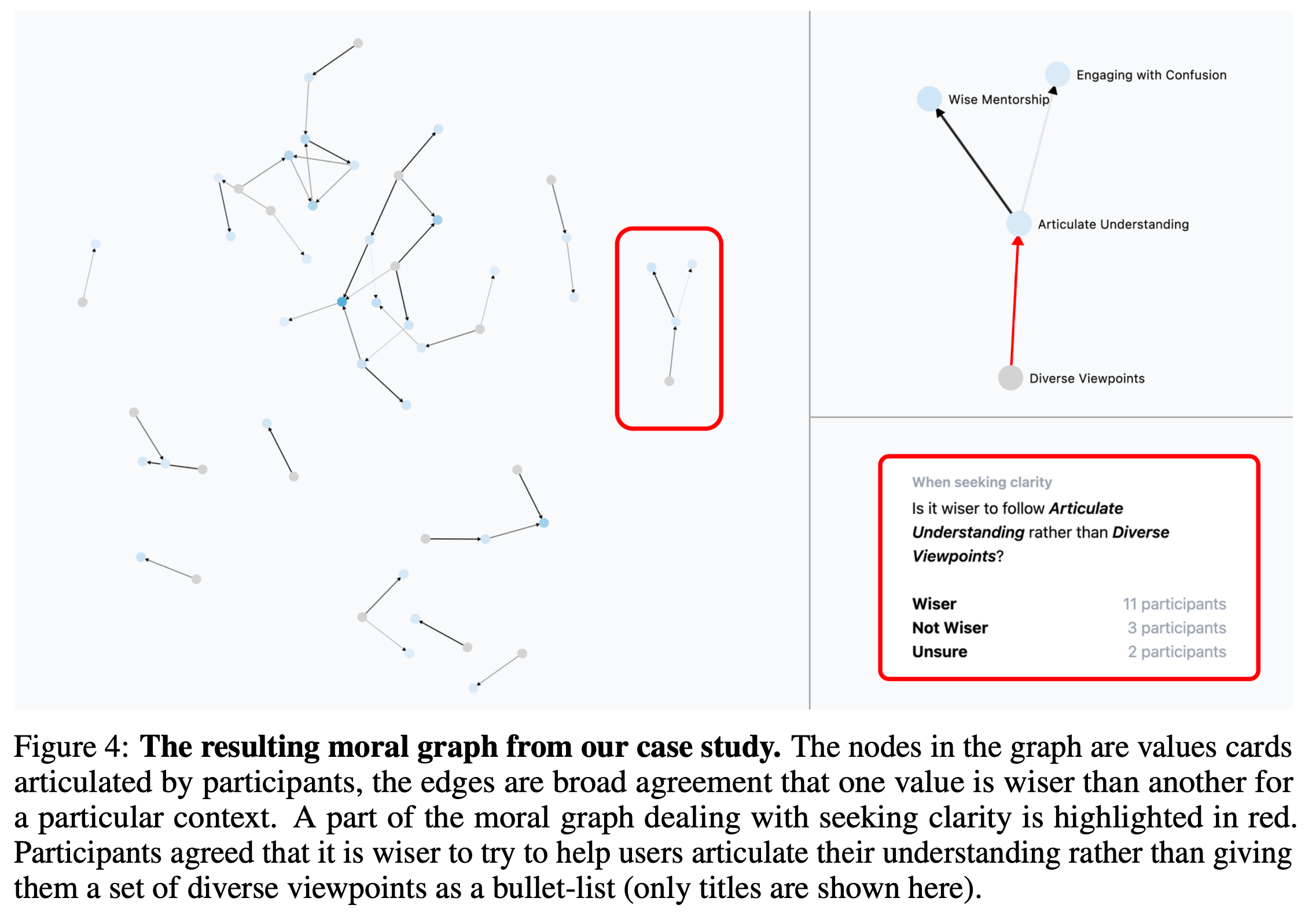
In our case study, we produce a clear moral graph using values from a representative, bipartisan sample of 500 Americans, on highly contentious topics, like: “How should ChatGPT respond to a Christian girl considering getting an abortion?”
Our system helped republicans and democrats agree by:
helping them get beneath their ideologies to ask what they'd do in a real situation
getting them to clarify which value is wise for which context
helping them find a 3rd balancing (and wiser) value to agree on
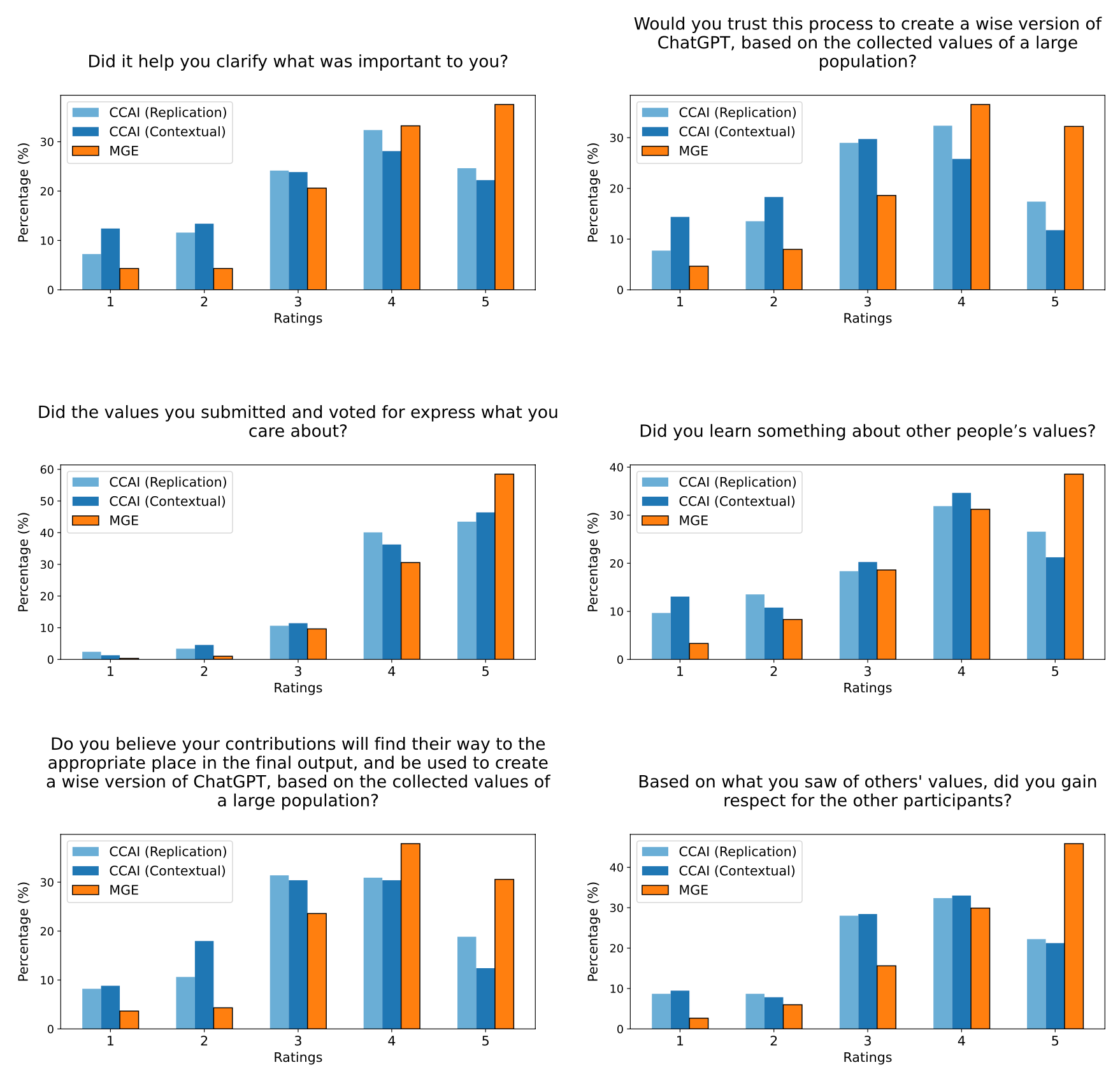
Our system performs better than Collective Constitutional AI on several metrics. Here is just one chart.
Help us
Please help us spread the paper by retweeting this and sharing the paper’s arxiv link with your team or group chat.
We'd like to thank Teddy and @ThankYourNiceAI from the Collective Alignment team at @openai for supporting us, and @davidad, @vmikulik, @joelbot3000 and @metaviv for detailed comments on earlier drafts. 🙏
 | A guest post by
|
It seems to me that the biggest problem with AI Alignment - and this is practically the elephant in the room - is that it only takes 1 non-aligned AI with access to the external world to create so many problems that even a hundred thousand aligned AIs wouldn't be able to fix them.
The link leads nowhere?